[Devlog 2] Notes that think and link
![[Devlog 2] Notes that think and link](/content/images/size/w1200/2024/11/nabu-banner.png)
What's new: A powerful AI note linking engine and UX improvements.
I've been using Nabu for a few months now, but naive link prediction is painful.
I recall jotting down something about the Bernoulli principle without mentioning "Bernoulli," and naturally, the suggestion engine drew a blank even though I had the note. This was particularly annoying since the whole point of this app is to uncover implicit connections.
My initial approach avoided machine learning, relying instead on a simple search-based method, but it's clear that root or inflection-based matching just won't cut it for nuanced, semantically related but lexically distinct notes.
Throwing AI at the Problem
Don't get excited, business bros, not LLMs.
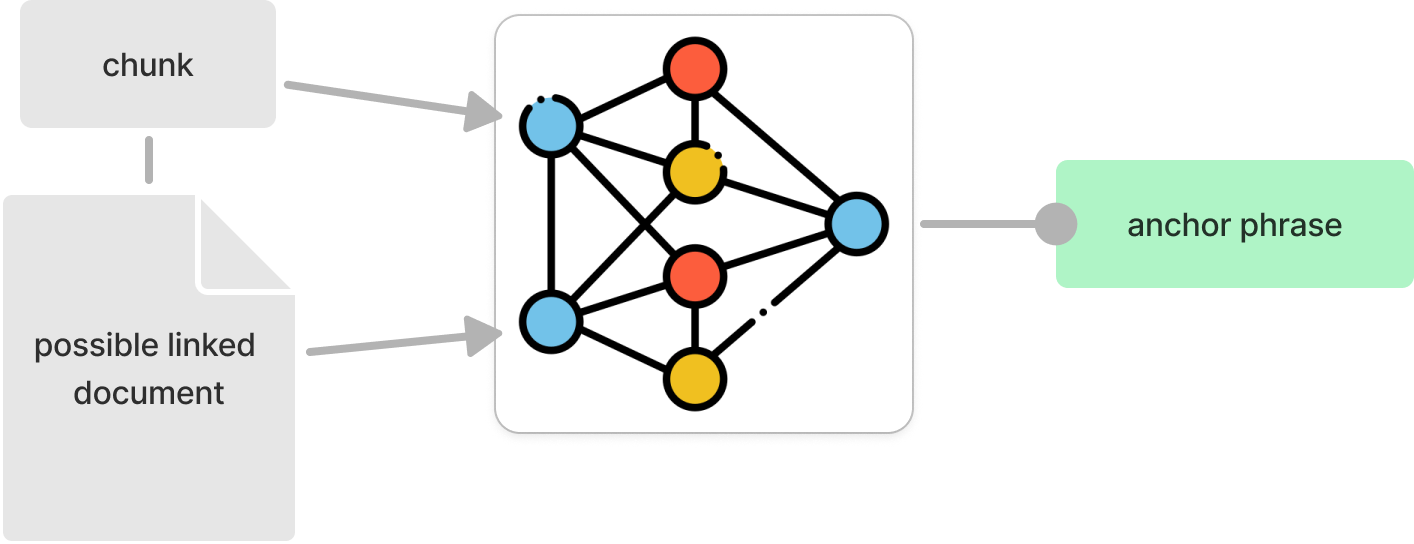
The challenge is moving from basic keyword matching to actual contextual understanding – in other words, knowing if a link exists and, crucially, pinpointing which words or phrases should be linked, similar to hyperlinks on Wikipedia pages.
Link prediction in graph machine learning is most simply formulated as a binary classification problem (link or no link), and introducing edge features to make it multi-class, as we need a phrase, not just yes or no, is a lot of effort. A more straightforward supervised contrastive learning approach should suffice.
I sense this (and anything graph-related) is going to be a nightmare to scale, but just to get started, here's how I've framed the problem:
Source and Target Encoding: BERT encodes each chunk of the source document (input_X_chunk) and the potential target note (input_X_linkdoc)BERT.
Anchor Phrase: The target anchor phrase is also encoded as a padded BERT representation to help the model understand specific words or phrases worth linking to - this can be an empty string if no anchor exists.
Negative Examples: To improve precision, I'm generating negative examples. This will help the model avoid spurious link suggestions that aren't useful.

I wrote a web crawler Python script to scrape Wikipedia and populate the dataset. It grabs a tags from source documents, using the href attribute as the destination and the inner text as the anchor phrase.

Results
Initial results have been promising but not flawless. The training curves look odd, and there's a noticeable gap between validation accuracy and validation loss. This could suggest some generalisation issues or a need for hyperparameter tuning – but it's too early to tell.
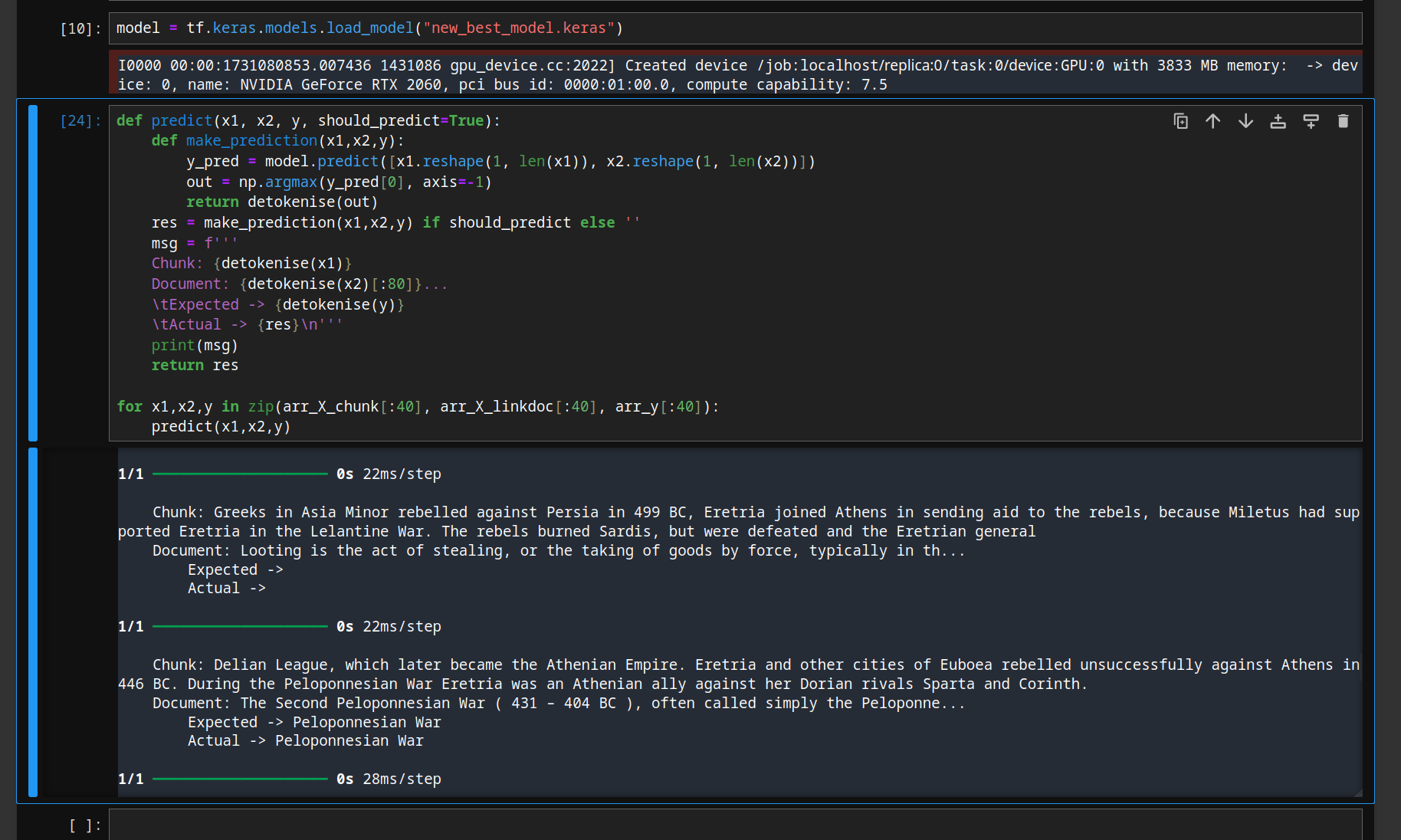
Validation metrics measure the model's performance on unseen data (sometimes called the testing set) that we check against during training. To illustrate, my current best model has a validation accuracy of 96%, meaning the model will correctly predict the anchor phrase 96% of the time on unseen chunks and destination documents. The validation loss, however, is 13%, meaning that when it's wrong, it is quite wrong. I had a professor who described validation loss as the model not capturing or 'losing' information in the testing data.

UI Improvements
In other news, I've made a few UX updates.
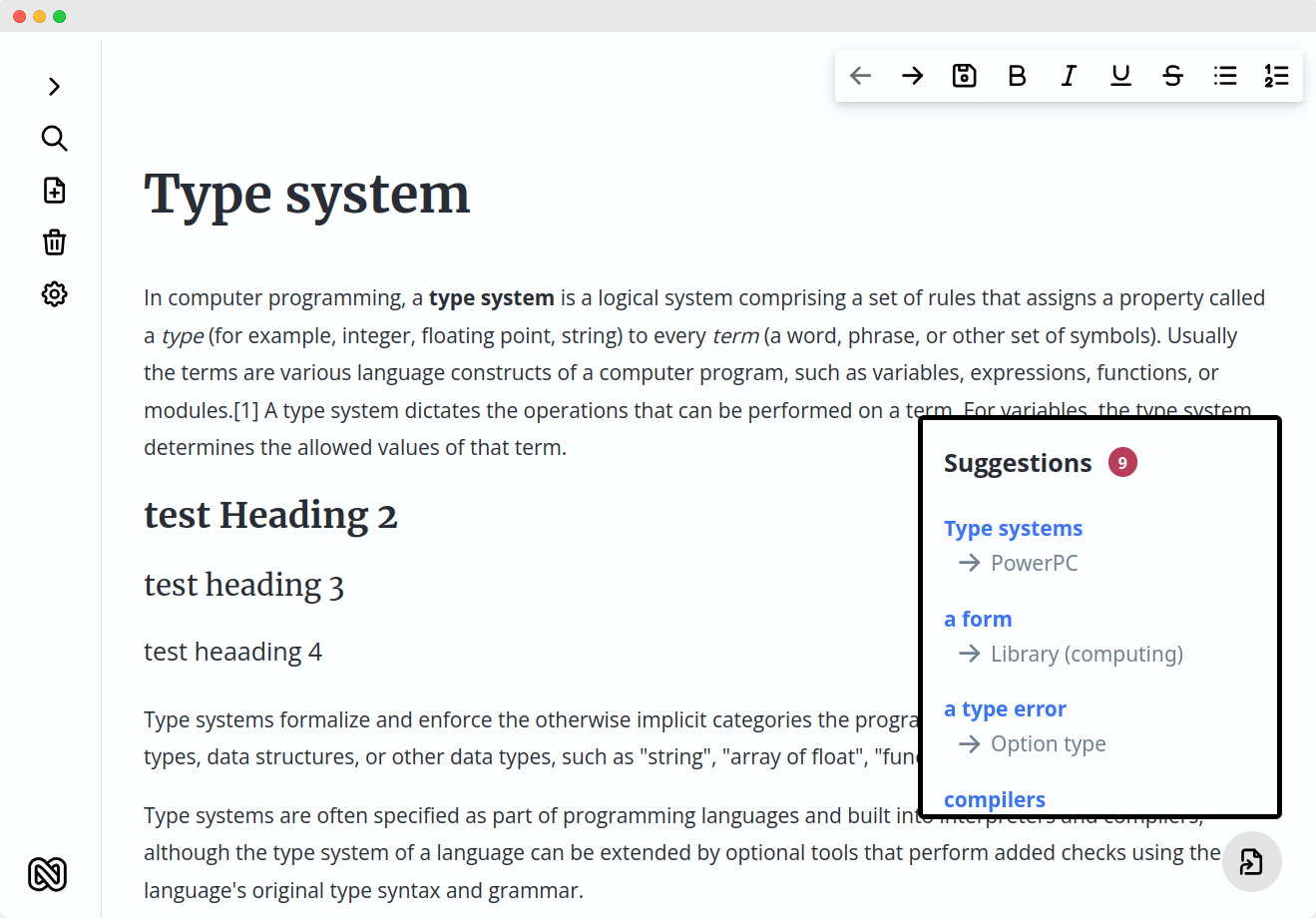
- Suggestions Panel: Instead of cluttering the inline text, link suggestions now appear in a side panel, keeping the main note interface cleaner. This will also simplify conflict resolution when introducing collaborative editing with CRDTs.
- Templating: Users can now create and apply templates, which facilitate note creation with predefined structures (e.g., book notes and daily logs).
- Image Support: Nabu now supports inline images.
- Vite for Build Optimisation: Migrated to Vite for faster and smaller builds and a snappier dev environment.
Next Steps
- Fine-tune the model to improve loss and reduce false positives. I imagine suggested links to nonsense would quickly become annoying.
- Build out infrastructure to
- Support the new ML backend.
- Reduce elastic search crashes.
![[Devlog 1] Why notes suck](/content/images/size/w600/2024/06/nabu-banner-1.png)